@专家协同机制识别圣经互文Investigating Expert-in-the-Loop LLM Discourse Patterns
Abstract
- 本研究探讨了大型语言模型(LLM)在识别和分析圣经科伊内希腊文献中的互文关系的潜力。
- 通过评估LLM在不同互文性情境下的表现,研究表明这些模型能够识别直接引用、暗示和文本间的回声。
- LLM生成的新颖互文观察和联系突出了其发现新见解的潜力。
- 然而,模型在处理长查询段落和错误互文依赖时存在困难,强调了专家评估的重要性。
- 本研究提出的专家-在-回路方法为互文研究提供了一种可扩展的方法,适用于研究圣经文献及其外的复杂互文性网络。
1. Introduction
- 互文性概念由朱莉娅·克里斯特娃(Julia Kristeva)提出,表明作者意图的意义应当理解为符合当时共同的时代精神。
- 类似于模糊神经网络的叠加层,作者的作品会转化输入语言“符号”的意义,使未来作品对这些符号的理解发生变化。
- 互文网络:
- 现代作品中的撒旦形象更多依赖于Milton的《失乐园》 而非《圣经》本身,尽管《创世纪》提供了撒旦的基础理解。在这一点上,Milton对撒旦形象的塑造比《圣经》的原文影响力要大,这正是互文性网络的一种体现。
- Kuznetsov等人(2022年) 的研究,他们提出了互文性图的概念,强调文本之间的影响并非线性发生,而是通过某种方式相互作用,类似神经网络中的权重变动和激活函数的作用。每个文本都在与前人的作品互动的过程中改变和塑造了对前作意义的理解。
- 圣经文本中的互文性挑战
- 许多圣经文本的创作时间无法精确确定,或者作者身份不明确,因此很难明确追溯某一文本是否直接依赖于另一部作品,或者它们之间是通过某种更为复杂的方式进行联系的。
- 圣经作者通常不会直接引用前人的作品,而是通过暗示、改写、引用或构建隐含的联系来传达思想。这使得在圣经研究中,互文性分析既丰富又复杂,很多互文性联系是隐性的,需要深入的学术解读。
- 专家评估在互文性研究中的作用
- 论文提出了“专家参与(Expert-in-the-Loop)”的概念,旨在通过人工智能技术(LLM)辅助专家进行互文性分析。具体来说,LLM可以自动识别和分析文本间的联系,而专家则负责最终的评估,判断这些联系是否真实且具有学术价值。
互文性(Intertextuality)💡
- 互文性是指文本之间的相互关系,Julia Kristeva在1980年的著作《语言的欲望:文学与艺术的符号学方法》(Desire in Language)中提出了这一概念。简单来说,互文性认为每一部作品都与其他文本相连,像是拼图的一部分,通过引用、灵感或语言模式与它们互动。例如,当你读到一本小说时,它可能暗指经典文学或历史事件,从而丰富其意义。
- 它认为任何文本都不是孤立存在的,而是与其他文本通过引用、典故和语言结构相互交织。
- 文本的意义并非固定,而是通过与其他文本的关系动态生成的,这可能对传统阅读方式提出挑战。
2. Background
2. 1 互文性
- 互文性的重要性:
- Richard Hays的开创性研究《Echoes of Scripture in the Letters of Paul》(1989年),这本书被视为将互文性研究引入圣经学术领域的重要作品。
- 然而,圣经互文性研究缺乏标准化的定义和方法论。
- 互文性识别的挑战:
- 圣经文本常常对前人文献进行隐晦的引用,甚至没有明确的引用或注释。
- LLMs与互文性研究:
- LLM:大型语言模型,如Claude,能够生成语境感知的词嵌入,并通过多层次的神经网络进行处理。
- 通过这种方法,LLM可以捕获语义和句法推理,处理长程依赖关系,并在输入文本中传递信息。
- LLM的变换器架构显著提升了其在几乎所有自然语言处理任务中的表现。
- LLM:大型语言模型,如Claude,能够生成语境感知的词嵌入,并通过多层次的神经网络进行处理。
2.2 LLMs
- LLM技术:
- LLM通过生成词汇的嵌入并进行注意力机制处理,能够对文本进行高级语言分析。
- 通过多层次的非线性映射,LLM能够处理语法和语义信息,分析文本的长程依赖。
2.3 相关工作
- Coffee等(2012) 的研究通过分析拉丁诗歌中的文本相似性,尝试发现文学作品之间的隐性引用。他们通过检测共享词汇来标识潜在的文本暗示,虽然这种方法有一定的成功,但它过于依赖词汇的表面重合,缺乏对文本更深层次相似性的分析,尤其是在处理隐性和间接的互文性时存在局限。
- Dai等(2023) 和Yu等(2024) 的研究则专注于LLMs的主题编码(thematic coding),他们发现LLMs能够在文本中发现主题,并与人工标注的结果进行对比,表现出了良好的主题识别能力。
- Khan等(2024) 的研究进行了 LLM 辅助的语料库编码,用于功能到形式的语用和话语分析
2.4 创新点
本文在已有研究基础上,提出了与现有研究相比的四大创新:
- 直接的定性互文性比较
- 任务目标是检索而非标注
- 增强而非自动化专家能力
- 非英语文本的处理
3. Definitions and Criteria
- 互文性(Intertextuality):
- 互文性被定义为不同文本之间的相互依赖,具体表现为直接引用、暗示或回响等关系。互文性不仅仅是引用前作的文本内容,它还包括了对先前文本的改编、延伸和再创作。
- 互文性可以是显性的(如直接引用),也可以是隐性的(如通过暗示、意象、主题等进行的间接联系)。
- 互文性类型
- 直接引用(Direct Quotation):这种关系通常是明确且易于识别的,文本直接引用了另一个文本的内容。
- 暗示(Allusion):暗示是指某一文本通过特定的词汇、结构或情境隐含地指向另一个文本。它通常没有明确指出来源,但能通过上下文推测出相似之处。
- 回响(Echoes):回响是比暗示更微妙的一种形式,可能只是在结构、主题或某个特定关键词上的相似,而不一定在词汇上有明显的重叠。
- 互文性判定标准(Hays, 1989):
- availability of the source to the author, volume (characterized by repetition, distinct patterns, prominence), recurrence of the citation by the author, thematic coherence, historical plausibility, history of interpretation, and satisfaction or sensibility.
4. Methodology
- 选定文本和情境:
- 选择6段文本,每段代表一个独特的情境。
- 通过Claude Opus提交这些文本并根据专家评估进行互文性强度的评定。
- 实验设计:
-
- 评估查询和语料库长度对检索效果的影响。
-
- 所有文本均为科伊内希腊文,由专门的互文圣经分析学者作为专家,评定互文性强度。
-
- 识别模型在不同情境中的失败模式,如假阳性、真阳性、可能性推测等。
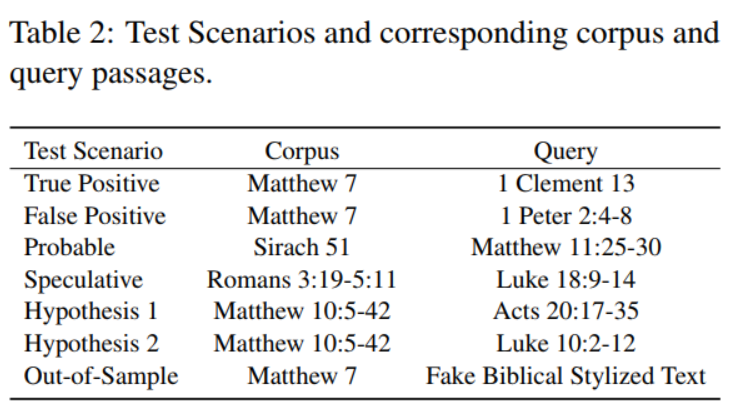
- 识别模型在不同情境中的失败模式,如假阳性、真阳性、可能性推测等。
-
5. Experiments
5.1 True Positive: Matthew 7 & 1 Clement 13
- 背景:
- 1 Clement 13中,作者似乎直接引用了《马太福音》7:1-2中的内容。
- 候选互文性:
- LLM识别出“你们用什么量器量人,也必用什么量器量你们”这一句与《马太福音》的直接引用。
- 语言模型检测到动词“κριθήσεσθε”(你将被审判)和“μετρηθήσεται”(它将被衡量)的词汇平行关系。
5.2 False Positive: Matthew 7 & 1 Peter 2:4-8
- 背景:
- 1 Peter 2:4-8并未直接依赖《马太福音》,但使用了“石头”这一隐喻,模型错误地将其标记为可能的互文性。
- 候选互文性:
- LLM识别了“石头”隐喻和“两条路”的主题,但这些引用更可能来源于《诗篇》和《以赛亚书》。
5.3 Probable: Sirach 51 & Matthew 11:25-30
- 背景:
- 《智者书》第51章与《马太福音》11:25-30之间的关系并未得到学术界的普遍认可,尽管有学者认为《马太福音》中的某些言论可能受到了《智者书》的影响。
- 实验结果:
- 模型识别了《智者书》与《马太福音》11:25-30之间的多种联系,特别是在“智慧的重担”这一主题上,尽管两段文本并没有直接引用对方。模型还注意到,感恩祷告和寻求智慧等主题在两段经文中都有体现,这为进一步的学术研究提供了新的见解。
5.4 Speculative: Romans 3:19-5:11 & Luke 18:9-14
- 背景:
- 《罗马书》3:19-5:11和《路加福音》18:9-14之间的关系常被学者讨论,但并未普遍认为这两段文本有直接的文学依赖。
- 实验结果:
- 模型发现《路加福音》18:9-14和《罗马书》3:21-4:8之间的主题相似性,尤其是在称义和义人的概念上。尽管这两段经文在直接引用上没有明显的联系,模型仍识别出了它们在语义层面的相似之处。
5.5 Hypothesis: Matthew 10:5-42, Acts 20:17-35, & Luke 10:2-12
- 背景:
- 研究者认为《使徒行传》的这段话可能与《马太福音》的话语有某种程度的关系,但这并未得到广泛学术支持。
- 实验结果:
- LLM发现《马太福音》10章和《使徒行传》20章之间存在多个联系,尤其是传道使命和困难的承受等主题。模型成功识别了两段文本之间的相似之处,尽管这些联系并未在学术界得到普遍承认。
5.6 Out-of-Sample: Matthew 7 & Fish and the Tree
背景:
为了评估LLM在没有预训练知识的情况下是否能识别互文性,研究者编写了一段全新的“鱼与树”的故事,故意融入了《马太福音》7章中的一些主题和词汇。
实验结果:
尽管这段故事完全是新的,LLM仍然能够识别出它与《马太福音》7章之间的词汇和主题相似性。例如,“树”与“好果子”的比喻,以及“根基”与“信仰”的关系。
6. Results and Observations
- 实验结果:
- LLM成功地识别了互文性的词汇对应和形态学数据,并进行了语义推理。
- 它能够区分直接引用和非逐字引用的不同,展示了语言处理的高级能力。
- LLM还能够根据文本的上下文,分析主题对应性,即使没有明显的词汇平行。
6.1 Evidence of Novel Intertextual Work
- LLM通过从给定文本中推理,而非从训练数据中提取无关信息,展示了其进行独立互文分析的能力。
- 在实验中,LLM揭示了多个潜在的新颖互文关系,如《士师记》51章与《马太福音》11:25-30之间的结构性关系。
7 结论
- 这项研究证明了 LLM 在识别和检查圣经文本中的文本互联关系方面的潜力。
- LLM 可以成为圣经学者有价值的工具,在使用简短查询和 1 到 3 章之间的语料库时表现出色。
- 该方法可用于大规模评估大量文本,以查找与查询段落的文本互联。
- LLM 能够检测圣经文本之间的直接引用、典故和回声,即使在非英语语言中也是如此。
- LLM 成功地识别了词汇对应关系、形态相似性、直接引用(改编或意译)、主题和结构上的相似性。
- 它展示了将语料库缩小到与文本互联分析最相关的部分的能力。
- 重要的是,LLM 展示了新型文本互联工作的证据,产生了在学术文献中似乎没有先例的观察和联系。
7.1 未来工作
- 未来的工作应该同时考虑图中的多个节点,以识别文本互联依赖的顺序,从而找到最可能的候选文本链。
- 未来的工作还应调查上下文召回效应的影响,例如在某些 LLM 中观察到的扇形效应。
8 局限性
- 该模型在处理较长的查询段落时遇到了困难,偶尔会产生错误和不合逻辑的判断。
- 在某些情况下,它也未能考虑共享的前文本,声称文本之间存在直接依赖关系,而共同来源更有可能。
- LLM 生成的文本互联候选者有时包括假阳性或微弱的联系,需要专家评估。
- 该模型在处理长查询时表现不佳,会产生基本错误和不合逻辑的判断。
- 当呈现相似的文本时,该模型可能不会考虑共享的前文本。
- AI 生成的候选者需要该领域专家的批判性眼光。
- LLM 根据数量、主题连贯性和可理解性提供结果,但没有评估可用性、复现性、历史合理性或解释的历史。